The SEV-SNP Exploit Is Coming From Inside The House. The Building Owner Is Helping Too.
This blog post discusses a recently patched privilege escalation vulnerability, CVE-2023-46813, in the Linux kernel that affected guests running as SEV-ES or SEV-SNP VMs.
Short Intro to AMD SEV
AMD SEV, SEV-ES and SEV-SNP are confidential computing technologies available on AMD EPYC CPUs that make it possible to securely run trusted VMs on an untrusted hypervisor. In very simple terms, SEV just encrypts the guest’s memory, SEV-ES added encryption and integrity protection of the guest’s registers and SEV-SNP added integrity protection of the guest’s memory. Guests communicate with the hypervisor via unencrypted shared memory pages.
VM Exits, AEs and NAEs
Conventional VMs depend on the hypervisor to emulate certain CPU instructions e.g. cpuid (queries information about the CPU itself), inb (writes a byte to an I/O port) and rdmsr (reads a machine specific register). Whenever one of these events occurs the VM exits to the hypervisor which then emulates the event by directly changing the VM’s registers and resumes the VM.
While this works well for conventional VMs, this approach does not work starting with SEV-ES because the guest’s registers are encrypted and the hypervisor has no way to emulate most events without access to the guest’s registers. To fix this a new exception type was added: Whenever an VM exit occurs that would require access to the guest’s registers a #VC exception is triggered in the guest. The guest will look at the VM exit that was supposed to happen, determine which registers are needed to handle it and then informs the hypervisor about the VM exit and associated registers through a structure called the GHCB (Guest-Hypervisor Communication Block). The hypervisor takes the information from the GHCB, handles the VM exit like a regular VM exit and writes the results back to the GHCB. Finally the guest reads back the results from the GHCB and resumes regular control flow.
There are a couple of VM exits that don’t require access to any registers and those events will not trigger a #VC exception. These exits are called automatic exits (AE) while the ones triggering a #VC are called non-automatic exits (NAE).
MMIO
There are two ways for an hypervisor to implement MMIO (memory-mapped I/O) regions:
- Map some memory into the region that’s shared between the guest and the hypervisor. This is very fast because it’s just a normal memory access for the guest, but the downside is that there’s no way for the hypervisor to be notified about the accesses. This method is appropriate for MMIO regions such as frame buffers.
- Set an invalid bit in the nested page table entry that maps the guest physical address of the MMIO region to a host physical address. Once the guest tries to access the that guest physical address, the CPU will notice the invalid bit and cause a “nested page fault” VM exit. When a nested page fault occurs the CPU also informs the hypervisor about the instruction bytes that triggered it. The hypervisor is supposed to decode the instruction and emulate the memory access accordingly. This is fairly slow because there’s a context switch on every access, but the upside is that the hypervisor can handle each access individually. This method is approriate for MMIO regions such as registers in PCI devices.
Both of these methods also work with SEV(-ES/-SNP) guests:
- The guest controls whether a memory page is shared with the hypervisor by setting a special bit, the C bit, in its pagetables. If the guest knows that a region is supposed to be a MMIO region, it can omit the C bit and accesses to the page are no longer encrypted. Both the hypervisor can see the same unencrypted memory.
- With SEV nested page fault VM exits doesn’t require any intervention from the guest. The hypervisor can decode the faulting instruction and access the registers as it would for a conventional VM. With SEV-ES and SEV-SNP nested page faults are considered non automatic exits and so the guest will have to handle them. Unlike the hypervisor, the guest is not given the instruction bytes of the faulting instruction. Instead it’s supposed to look at the instruction pointer at the time of the exception, decode the instruction from its memory and finally emulate it.
The Bug
It turns out that handling nested page fault exceptions in SEV-ES/SEV-SNP is inherently racy: The guest kernel isn’t provided with the instruction bytes of the faulting instruction, so it has to go and fetch them itself, but by the time it’s doing that the instruction bytes might have already been changed by another thread. As a result the kernel shouldn’t assume that the instruction it has fetched is the one that caused the #VC exception. Usually when the CPU tries to access memory it checks that it’s currently allowed to access that memory. Those permission checks happen before a #VC exception would be triggered. The problem with the way Linux was handling nested page fault exceptions in its #VC handler was that it was incorrectly assuming that the CPU had already checked memory permissions for the instruction Linux decoded. This is vulnerable to the following race condition:
- Thread 1 executes the instruction
mov [MMIO], 1234at address0x414141- This instruction tries to write the value
1234to addressMMIO. - The CPU checks that it’s allowed to access
MMIO. MMIOis MMIO region with an invalid bit set in the nested page tables, so a nested page fault #VC exception is triggered.
- This instruction tries to write the value
- Thread 2 changes the instruction at
0x414141tomovs [KERNEL], [USER]- This instruction reads the values at address
USERand writes it to addressKERNEL.
- This instruction reads the values at address
- On thread 1, the kernel decodes the instruction at
0x414141and seesmovs [KERNEL], [USER]and emulates it without permission checks.
When neither USER nor KERNEL point to a MMIO memory region, Linux would emulate this as such by simply copying the value from USER to KERNEL 1. This is a problem because the write to KERNEL shouldn’t be allowed to happen as regular usermode programs shouldn’t have access to kernel memory from usermode. As a result this vulnerability can be used to write arbitrary kernel memory. By swapping the USER and KERNEL arguments this can also be used to read arbitrary kernel memory instead.
Another implementation detail that is very convenient is that Linux will properly forward page fault exceptions while emulating the movs instruction. This means that if KERNEL is not a valid address, the kernel will not crash, but forward the fault to the user which can handle the exception. This can be used to check whether an address is valid.
There is one significant problem with this attack: It relies on the user having access to a MMIO region. This is commonly not possible because usermode programs rarely directly communicate with the devices that expose these MMIO regions. There’s a way to solve this though: Remember how the hypervisor is explicity untrusted in SEV’s threat model? If we assume the hypervisor is malicous, it can change a regular user mapping into a MMIO memory region by simply setting an invalid bit in the nested page table for that address. As a result a malicous hypervisor can help an unprivileged process in the guest achieve privilege escalation.
Exploit
This vulnerability gives us the following exploit primitives:
- Check whether an address is valid
- Arbitrary kernel read
- Arbitrary kernel write
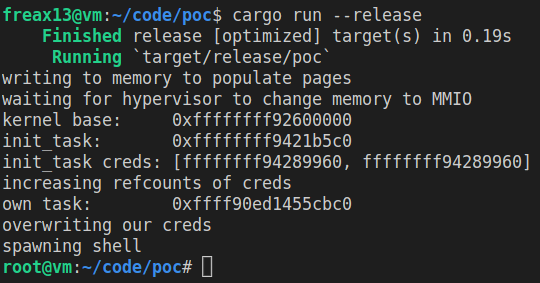
My proof of concept exploit performs the following steps to escalate it’s privileges:
- Allocate a huge chunk of memory and write to it to force the kernel to populate it.
- Wait for the untrusted hypervisor to execute the custom
attackcommand in QEMU. Once this command has been executed, the host will set an invalid bit in the nested page table entry for the guest physical address at0x1f8b0c000and therefore change it to be a MMIO region. The hope is that this address is belongs the the big chunk of memory allocated in step 1. - Continously write to all pages in the allocated chunk of memory using a
mov. Once the page that was turned into a MMIO page is hit, the write will trigger a #VC exception. Unlike for themovsinstruction, for themovinstruction the kernel will check that the memory region was supposed to be an MMIO memory region. Once the kernel notices that the region wasn’t supposed to be a MMIO region it delivers aSIGBUSsignal to usermode. The PoC uses this signal to detect when it hit the page that was turned into a MMIO page. - Use primitive 1 to find the base address of the kernel by trying all possible values.
- Use primitive 2 to read from kernel memory in order to find the
inittask. - Use primitive 2 to iterate over the
inittasks children to find thetask_structassociated with the PoC’s process. - Use primitive 2 to read the credentials of the
inittask (i.e. root credentials) and use primitive 3 to copy them over to the PoC’s task. This escalates the task’s privileges to root. - Spawn a shell.
Here’s a video demonstration of the PoC running on an unpatched system: https://www.youtube.com/watch?v=6D90uO_PgoU.
Patch
This vulnerability was patched by restricting MMIO accesses to the kernel because of the complexity involved in preventing the race condition. It turned out that there isn’t any usermode code interacting with MMIO regions anyways, so this doesn’t break things in practice.
A variant of this bug exists for I/O instructions which suffer from the same race condition between execution of the instruction, permission checks by the CPU and decoding of the instruction in the kernel. This variant was patched by checking the I/O port permissions again in the kernel before emulating the instruction.
Footnotes
-
Linux can only know which address triggered to nested page fault if the instruction has a single memory operand.
movshas two memory operands, so in this case Linux doesn’t know whether the read from the source, the write to the destination or both have caused the nested page fault. It solves this by emulating the instruction by splitting it up into an individual read followed by an individual write. If either of these accesses causes a nested page fault Linux can then know the addresses that caused fault. If neither access cause a nested page fault this is will just copy the value. ↩